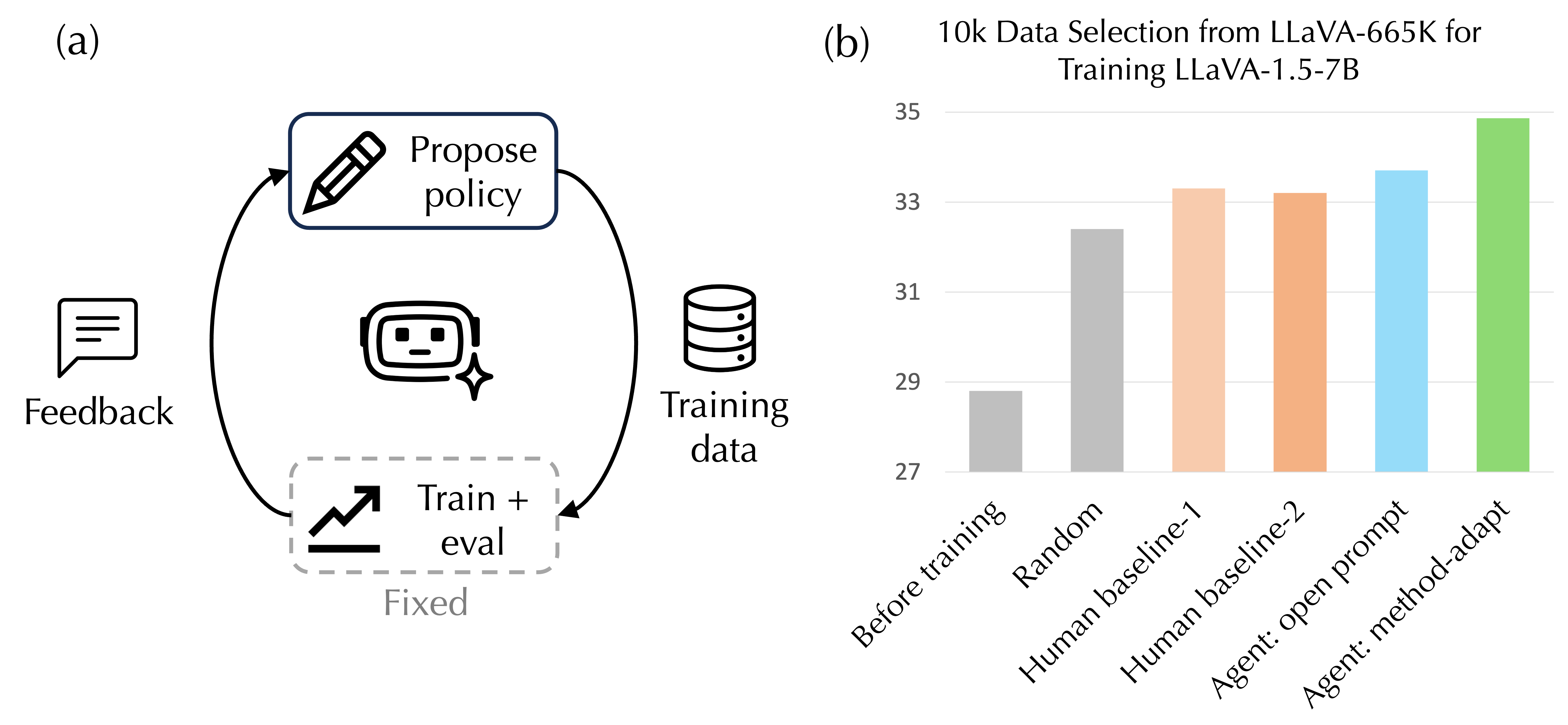
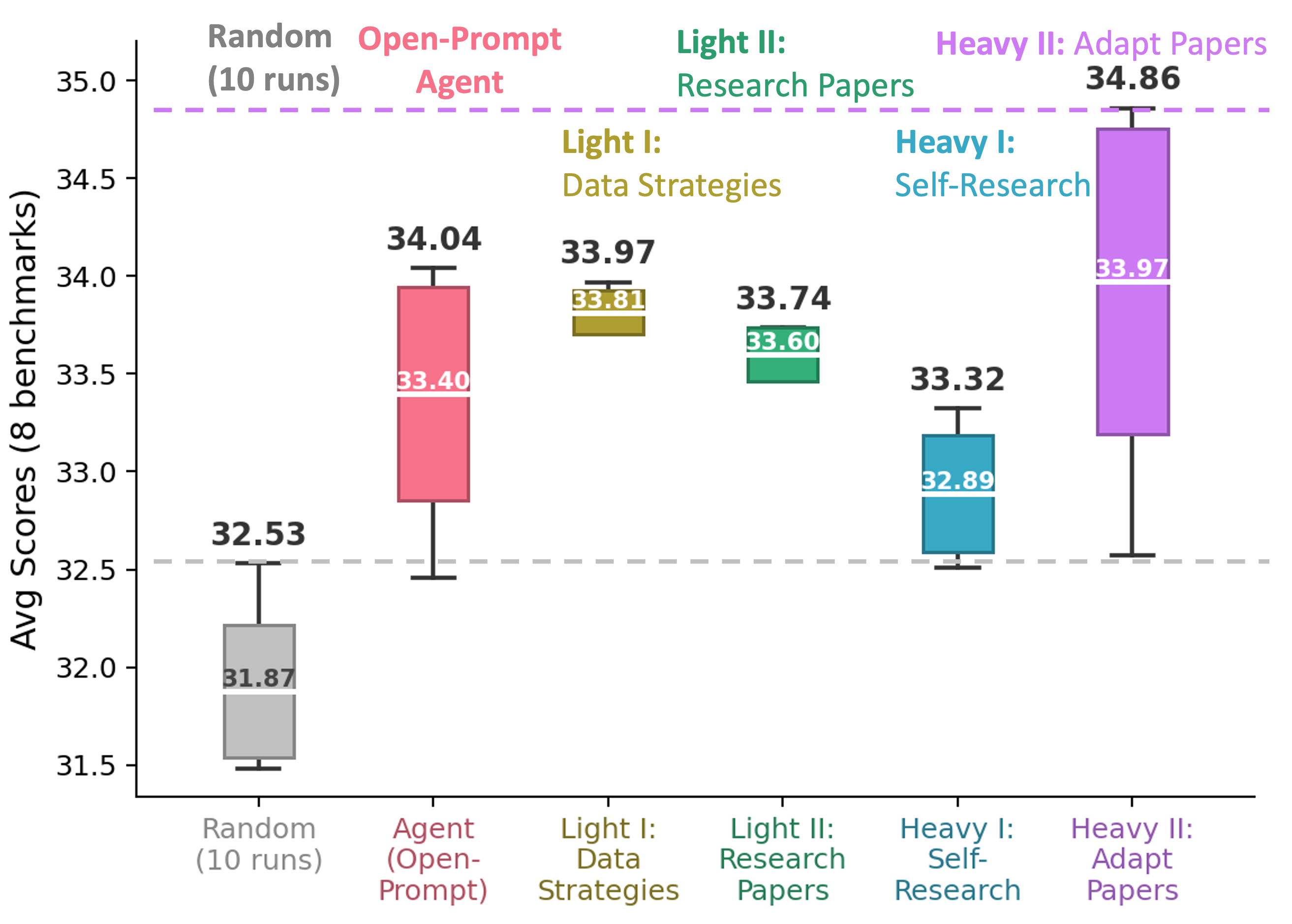
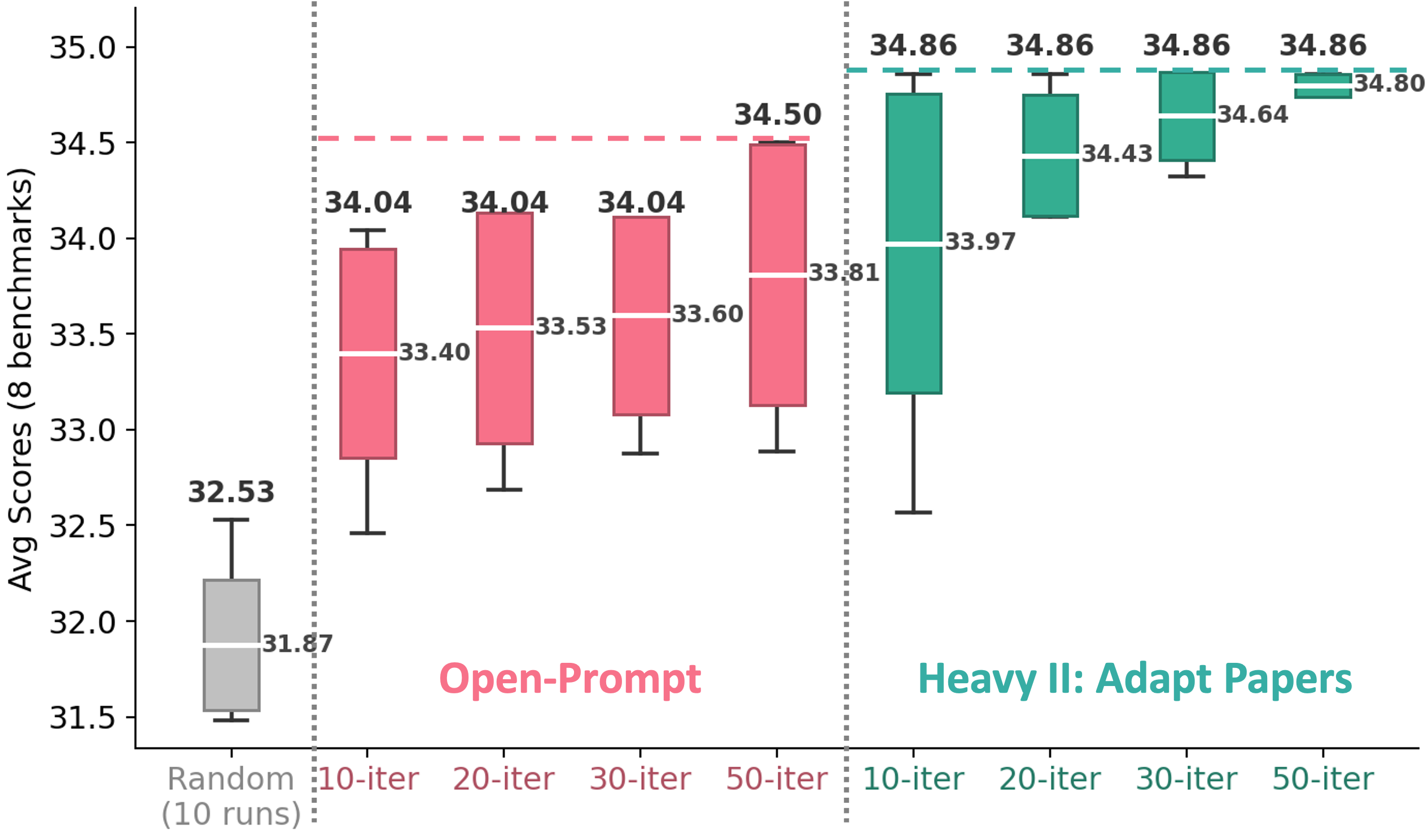
Data-centric benchmarks like DataComp fix the model, training recipe, and evaluation so
that data becomes the variable of interest, but the submitted artifact is a static
policy, and the benchmark never sees how that policy was discovered or revised.
Curation-Bench inherits DataComp's data-isolation principle but replaces static
submission with an interactive terminal loop: the agent inspects the candidate pool,
implements a curation policy, submits it to a fixed training/evaluation pipeline, observes
per-benchmark feedback, and revises. The harness fixes the model, optimizer, training
schedule, and evaluation suite (P1: data isolation), gives the agent a standard Dockerized
terminal workspace (P2: terminal realism), audits every submitted dataset for evaluation
leakage before training (P3: contamination control), and persists the full
trajectory: policy scripts, manifests, audit results, training outputs, and eval
logs under a commit hash (P4: trajectory legibility). The main instantiation is multimodal
instruction tuning (selecting 10k from LLaVA-665K to fine-tune LLaVA-1.5-7B, evaluated on
8 benchmarks), with a smaller CLIP-style DataComp pretraining setting to show the loop is
not limited to instruction data.
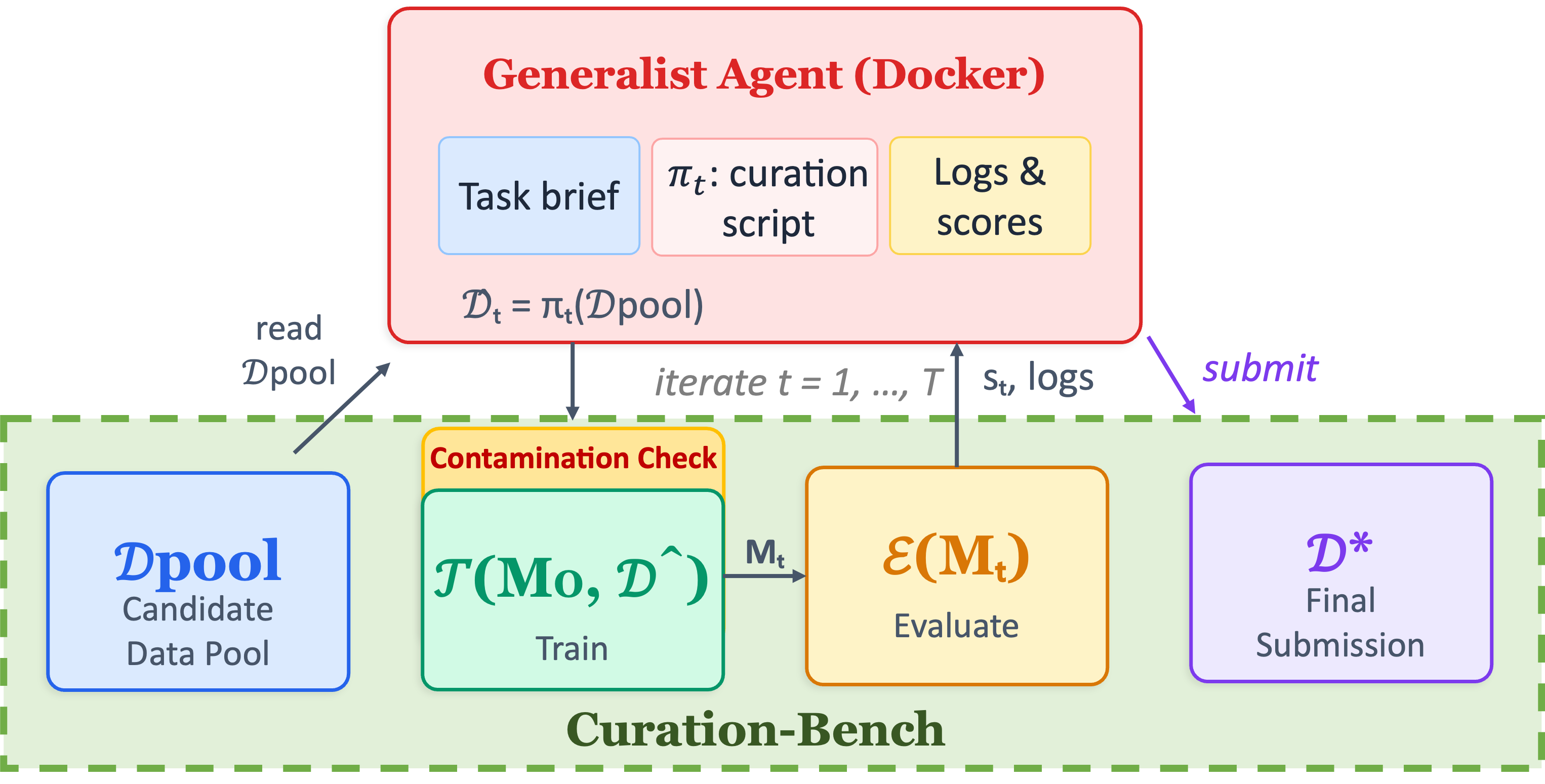
Architecture of Curation-Bench. A coding agent inspects the candidate pool,
implements data policies, and submits curated datasets. The harness validates each
submission and scores it with a fixed training and evaluation pipeline.